



Training machine learning models is hard, and training models that perform well is one of the top priorities of any data scientist. However, an often overlooked fact is that once a model is trained, deploying it on a large scale for inference can be another huge challenge in itself! Consider some of the problems that models created with finetune, indico’s python library for the task, face once deployed for production:
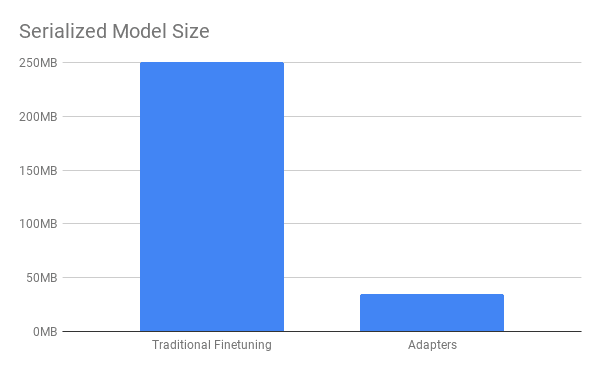
Large Files: Saved models can exceed 250MB, even after float precision reduction. These large files are difficult and expensive to store, and have to be transferred over network for use in production.
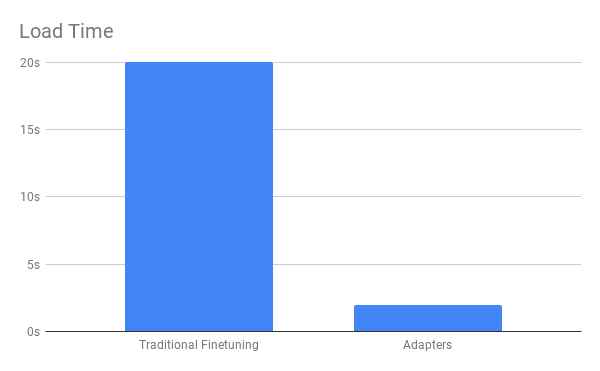
Latency: Before a model can be used, all of its parameters must be loaded into memory, which forces TensorFlow to perform a slow graph recompilation. Combined with transfer and loading of large files noted above, these factors contribute to up to 20 seconds of overhead when trying to predict using a finetuned model!
Caching Issues: We want our deployed models to be able to handle requests quickly, and that means parameters have to remain cached in memory for each model. Since switching out models automatically triggers graph recompilation, each model has to remain cached on a separate processor. Serving a dozen different models would require a dozen GPUs running constantly, which is prohibitively expensive, so inference requests have to be handled with less performant CPUs, further exaggerating latency and throughput issues.
Parameter inefficiency: Even if finetuned models use the same original featurizer, such as BERT or GPT, nearly every weight in each model is changed during training. This means that the vast majority of parameters in a model have to be saved, stored, transferred, and loaded – even if they only differ slightly from their starting point.
Given these problems, it would be very convenient to have a method of finetuning models that only trains some of the present weights. That way, saved file sizes would be smaller, and loading times faster, since only the small numbers of weights that are changed during training would have to be handled.
One solution to this problem might be to train only a subset of the layers of the Transformer. However this approach still encounters problems with graph recompilation, and in practice this approach causes significant degradation to model prediction quality. Fortunately, a more elegant solution is possible with finetune’s new DeploymentModel, which leverages the adapters idea from Parameter-Efficient Transfer Learning for NLP along with some clever software engineering to speed up model inference and reduce saved model sizes at a minimal cost to model accuracy.
The adapter is a small block of feedforward layers that are mixed into each layer of the Transformer architecture. In our case, it downprojects its input to dimension 64 by default, before reprojecting to its original size. As described in the paper, the adapter uses a skip-connection so it can initialize to identity before training; otherwise, the model will not converge.
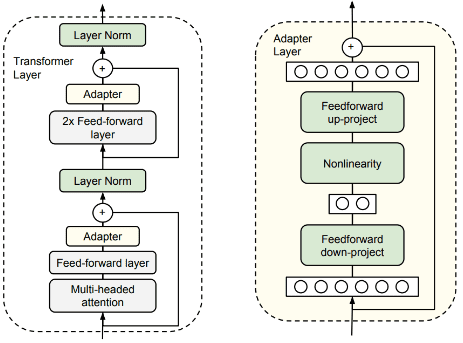
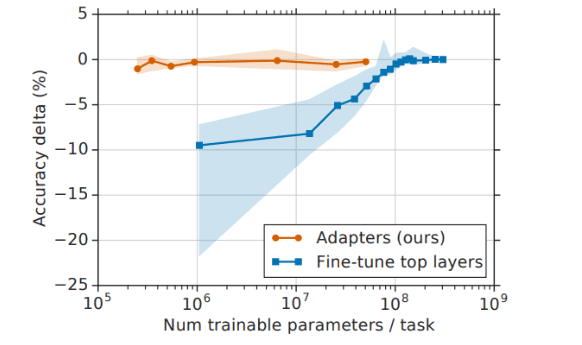
During finetuning, we modify only the adapter blocks and layer normalization weights – since they have very few parameters – leaving everything else unchanged. Amazingly, the shift from finetuning the entire model to finetuning with orders of magnitude fewer parameters causes nearly no harm to accuracy:
When combined with our custom DeploymentModel, adapters provide numerous other advantages. Since we only need to track the changed weights, model save files become much smaller when we save our model. The DeploymentModel leverages this fact by holding the large static featurizer loaded in memory, while it selectively switches out adapter and layernorm weights when running inference a different model is desired. This method preserves the featurizer graph, which bypasses TensorFlow’s expensive recompilation. Thus, we only have to deal with the overhead of graph compilation once, and we can then amortize that cost over multiple prediction runs with multiple models.
Let’s check out how anyone can take advantage of adapters and the DeploymentModel using finetune. We train a simple classifier, making sure to enable adapters in its configuration:
from finetune import Classifier from finetune.base_models import GPTModel model = Classifier(adapter_size=64, base_model=GPTModel) model.fit(X,Y) model.save(‘classifier_using_adapters.jl’)
The DeploymentModel allows us to use the weights from our trained classifier for fast loading and prediction. Note that we specify the base model used and load the featurizer before loading in the custom model, to incur the one-time overhead of graph compilation up front:
from finetune import DeploymentModel deployment_model = DeploymentModel(featurizer=GPTModel) deployment_model.load_featurizer() deployment_model.load_custom_model(‘classifier_using_adapters.jl’) preds = deployment_model.predict(X)
As described previously, the DeploymentModel can also swap out weights without requiring a reload of its featurizer. See this in the example below, assuming there is also a previously trained regressor on file:
deployment_model = DeploymentModel(featurizer=GPTModel) # Load the base featurizer and incur a one-time cost deployment_model.load_featurizer() # Quickly load a target model and corresponding adapter weights deployment_model.load_custom_model(‘classifier_using_adapters.jl’) classifier_preds = deployment_model.predict(classifier_X) # Quickly swap out the target model and adapter weights of another model deployment_model.load_custom_model(‘regressor_using_adapters.jl’) regressor_preds = deployment_model.predict(regressor_X)
With the DeploymentModel, the time from loading to the end of predicting is a mere 2 seconds (compared to over 20 seconds before), and it works with a file that is nearly 10x smaller!
The DeploymentModel works by splitting the model into two separate graphs, using two estimators from the TensorFlow Estimator API – one estimator delivers the large featurizer, the second loads the much smaller target model that is customized for each task. The target estimator is reloaded in each call to predict, but its overhead is trivial due to its size. Of course, the key advantage is that the featurizer estimator remains cached between all calls to predict and load_custom_model, and only edits a subset of necessary weights when loading new models. Check out the source code in finetune here.
With customizable adapter sizes and support for several base models, prediction is more efficient with no loss of freedom. By bundling an academic advance with some clever software engineering, production model finetuning has the potential to be cleaner, faster and dramatically more practical than before.




