




Recognizing patterns comes naturally to us. Whether we’re learning a new language, guessing the artist of a song we’re hearing for the first time, or even recognising an old friend, our brains use patterns to simplify complex mental tasks. In fact, our brains are so hardwired to use pattern recognition as a shortcut, we even find patterns in random data!
Choosing an outfit for the day or purchasing new clothing are some ways many people more consciously employ pattern recognition in day-to-day life. You may not think your brain is using patterns shaped and tweaked by years of data when you assess whether your shirt and pants match, or whether a discount pair of shoes will fit your ‘look’, but your brain has learned what is aesthetically pleasing and culturally appropriate by seeing how other humans dress themselves almost every day of your life. Even if you, like myself, don’t consciously match clothing as you get dressed for the day, you still use pattern recognition to recognize which clothing is socially acceptable in different social situations (although my mother might be skeptical this part of my brain is working correctly, after having seen my attempts to dress myself for formal occasions).
The Task
So, it’s safe to say that most humans are good at recognizing clothing patterns and similarities — but how well could a computer perform at this task? Using indico’s image features API, I designed a simple proof of concept of its ability to find similar clothing to an input photo. I chose this task instead of a more complex one because:
- It’s conceptually very simple. Looking for similar clothing is a much easier problem to wrap your head around than looking for matching clothing, meaning I can write cleaner (and clearer!) code in less time.
- It’s more generalizable. Image similarity is a building block for a wider variety of applications than the more domain specific task of clothing matching.
- It’s easier for me to assess how well it’s working. Even though I’m just hacking this together and will not be mathematically assessing progress, I trust myself to recognize whether clothing is similar more than I trust myself to assess whether it matches. In a similar vein, clothing similarity, although still being measured subjectively, is more universal than clothing matching.
- It has more obvious applications. Although most people don’t want a computer to tell them how to match their clothing (although some of us might benefit from such advice), there are obvious e-commerce applications for image similarity matching, such as a consumer wanting to find a less expensive, still in stock, or more ethical article of clothing similar to one of which they have a picture.
Getting Started
For my dataset of images, I selected 2000 random images of women’s clothing from the Lord and Taylor product feed. If you want to follow along, those images, as well as skeleton code and a few helper functions, can be cloned from the ‘skeleton’ branch of the GitHub repo. Once you’ve cloned the branch, open up main.py.
First, let’s set how many images we’re going to analyze and compare using the constant N_IMG. There is no reason to compare a large number of images before we’ve worked out any bugs; we don’t care how pretty our results are if the script won’t even run! I’ve set N_IMG to 500 in the skeleton, but feel free to set it even lower to get stuff working with less wait time.
Once we’ve set N_IMG, we’ll need images to actually compare! I’ve written a helper function make_paths_lists that returns a list of N_IMG image file names from the clothing_images directory.
def run():
paths = make_paths_list()
run()
Luckily, the indicoio Python library can take in paths for all of its image functions, so we don’t need to even read in any image data! We want the image feature vector for each of these images, so we’ll need the
Using indico
First we’ll need to install the indicoio Python library. To do this just go to your terminal and install using pip:
$ pip install indicoio
I like to set my API key in an environment variable, $INDICO_API_KEY, which the client library will automatically know to look for, but you can also put your API key in your configuration file or pass it in directly when you call the API.
Awesome! Now we’re ready to make a call to indico to get the image features for our 500 images! Start by adding the indicoio library import to the code.
import math import os from random import sample import cPickle as pickle from scipy import spatial from PIL import Image import numpy as np import indicoio
Now let’s update our method make_feats(paths), which takes in a list of image file paths, and should return a list of image feature vectors. Indico should be able to handle a batch request of size 500, so for now the method just looks like:
def make_feats(paths):
return indicoio.image_features(paths, batch=True, v=3)
We set batch=True since we are passing in a list of images, not a single image, and set v=3 to use Version 3, currently the most recent version of our image features model.
Our run() function should now look like this:
def run():
paths = make_paths_list()
feats = make_feats(paths)
run()
Fleshing Out Our Code
Great! We have a list of image features (4096, to be exact) for each of our 500 stock photos of clothing. How does that help us? How are we going to use those vectors of information to predict which clothing is the most similar? Similarity between the images will be captured in similarity between the feature vectors, so, naively, we can guess how similar two articles of clothing are by determining the Euclidian distance between the feature vectors of those two articles. The smaller the distance in 4096th dimensional space, the more similar two articles of clothing are likely to be!
To test this theory, I wrote a helper function calculate_sim(feat). This function takes in a list of feature vectors, determines the Euclidian distance between each pair of feature vectors, and returns a list of sorted lists of image indexes from smallest to largest distance. For example, the fifth image would be represented by the feature vector with index 4 of the input array. In the output array, index 4 would be a list of image indexes and their distances, starting with (0,4), since the fifth image has a Euclidian distance of zero from itself. To get the similarity rankings update your run() code like so:
def run():
paths = make_paths_list()
feats = make_feats(paths)
similarity_rankings = calculate_sim(feats)
run()
Finally, let’s get a look at how our similarity ranking performed! Updating our code as follows will choose three images from the data at random and generate a 2×5 grid with the ten best matches for each (including the image itself).
def run():
paths = make_paths_list()
feats = make_feats(paths)
similarity_image = calculate_sim(feats)
chosen_images = sample(xrange(N_IMG), 3)
for k in range(len(chosen_images)):
chosen_img = chosen_images[k]
similarity_image(chosen_img, similarity_rankings, paths)
run()
At last, it’s time to run our code! Open up your terminal again and call the script.
$ python main.py
The code should take a little while to run, but eventually, three images should pop up. The first one of mine looks like this:
Not too bad, but could be better! The very first image of the stippled dress is the one the others are matching against. Most of the matches are dresses of similar length, but two are of white shirts that don’t look very similar at all. I feel confident we can do better simply by looking at more images.
Making Our Code More Robust
Before increasing our number of input images, we have to make a few changes in our code to prepare. First of all, it took forever to generate those paths and similarity rankings arrays. To minimize how often those need to be recalculated, update your run code as follows:
def run():
try:
paths = pickle.load(open('paths.pkl', 'rb'))
except IOError:
paths = make_paths_list()
pickle.dump(paths, open('paths.pkl', 'wb'))
try:
similarity_rankings = pickle.load(open('similarity_rankings.pkl', 'rb'))
except: IOError:
feats = make_feats(paths)
similarity_rankings = calculate_sim(feats)
pickle.dump(similarity_rankings, open('similarity_rankings.pkl', 'wb'))
chosen_images = sample(xrange(N_IMG), 3)
for k in range(len(chosen_images)):
chosen_img = chosen_images[k]
similarity_image(chosen_img, similarity_rankings, paths)
run()
As we increase our number of images to analyse, there may soon be too many for indico to process in one request without timing out. Since we know that the server could handle 500 images, we can update make_feats as follows, so it will run no matter how large N_IMG is:
def make_feats(paths):
chunks = [paths[x:x+100] for x in xrange(0, len(paths), 100)]
feats = []
for chunk in chunks:
feats.extend(indicoio.image_features(chunk, batch=True, v=3))
return feats
Including More Images
Finally, let’s increase N_IMG to 1000 before running our code again. Overall, the results should look better! I saved the index of the stippled dress image and checked the ten closest matches again:

Much better! With more images to chose from, the top ten (or nine, if you don’t count the image itself) matches are all dresses of similar length and palate. The second best match is even another dress with black and white stippling!
One final time, let’s increase N_IMG to 1500. Make sure to delete the similarity rankings and paths pickles, so that they will be recalculated with N_IMG=1500. This final increase yields the following matches for the stippled dress:

Why It Works
The key to understanding why our simple nearest neighbor search works as well as it does is understanding the image feature vector. Since we let the indico api do the machine learning heavy lifting, those vectors are a bit of a mystery from a black box.
def make_feats(paths):
return indicoio.image_features(paths, batch=True, v=3)
The image feature vector for each image is an array of 4096 floats. Each of those floats represents a feature of the image, such as color attributes, sharpness, or horizontal stripey-ness. Many of these features are far more abstract and would not be qualities a human would use, at least consciously, to distinguish images. By finding the images with the smallest Euclidian distance from each other, we are minimizing the difference between these 4096 attributes!
Doing More
If you enjoyed this tutorial, it’s worth exploring other applications for image similarity prediction. Similar techniques can also be used for a variety of problems, including image classification and edge detection. If you hack something cool with our APIs, let the indico team know! Also, if you’d like to play with a more refined version of this script, check out the clothing similarity demo on our website.
Other Image Similarity Visualizations
As a bonus, check out this cool t-SNE visualization of our stock images!
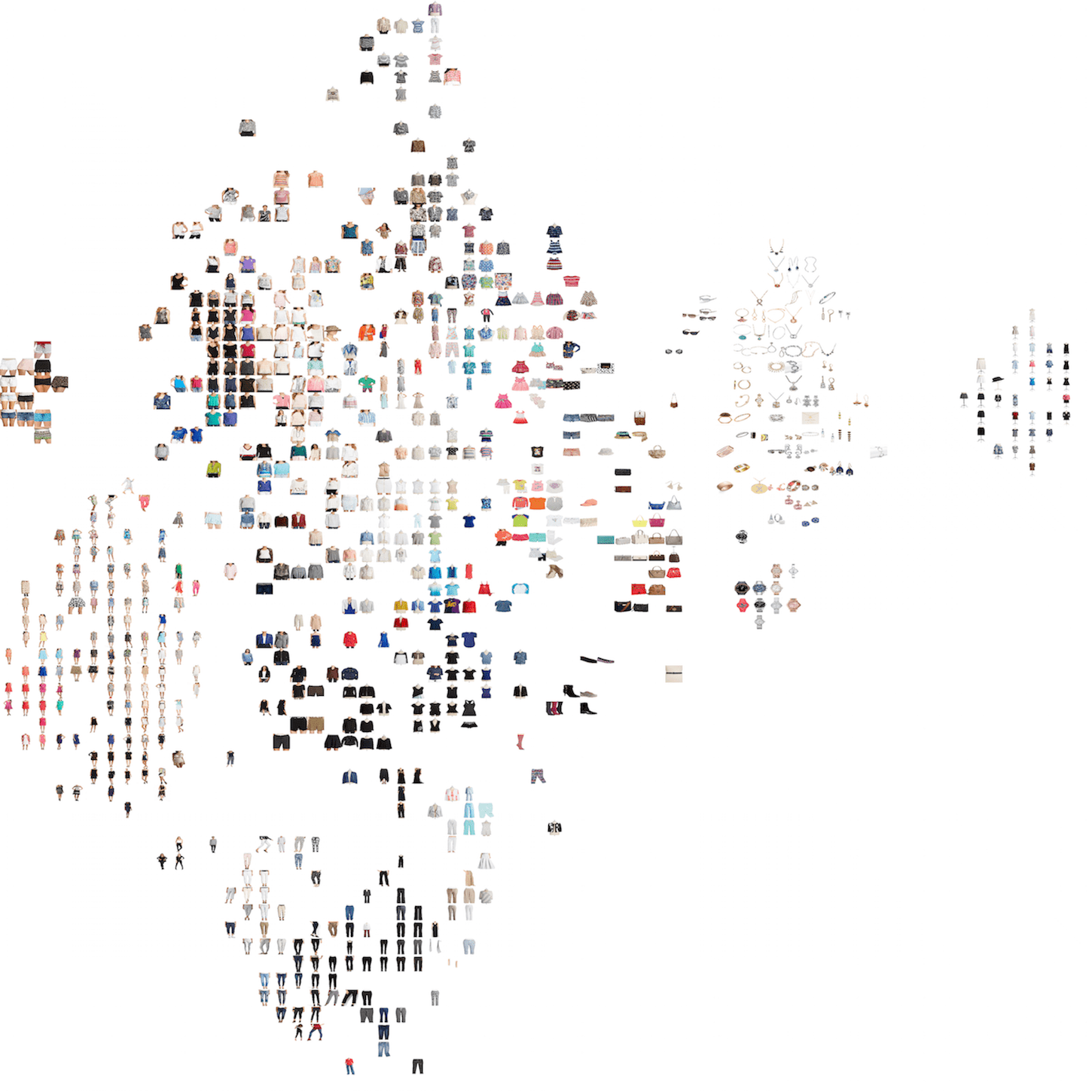
Curious how this works or want to make your own? Check out Visualizing with t-SNE to learn everything you need to get started.
Effective January 1, 2020, Indico will be deprecating all public APIs and sunsetting our Pay as You Go Plan.
Why are we deprecating these APIs?
Over the past two years our new product offering Indico IPA has gained a lot of traction. We’ve successfully allowed some of the world’s largest enterprises to automate their unstructured workflows with our award-winning technology. As we continue to build and support Indico IPA we’ve reached the conclusion that in order to provide the quality of service and product we strive for the platform requires our utmost attention. As such, we will be focusing on the Indico IPA product offering.
