



Email, a tool invented over 45 years ago, remains the most trusted form of online interaction as it stands decentralized in a world of social applications. With a little help from the indico Sentiment API, you can quickly go from having a large corpus of written emails to a visualization of how the sentiment in your writing has changed over time.
Before diving into the analysis you can get an email.json file with your personal emails by following these simple steps:
- Set up your email with Context.IO
- Enter your credentials in the download.py script as strings
- Wait 30min for your email to sync with Context.IO
- Run the download.py script
Now let’s dissect the em.py file used to analyze your emails starting with the imports. Before continuing, make sure you have registered at indico.io to get an API key. This will set you up with 1 million free calls per month; more than enough to complete this tutorial with plenty of calls to spare.
The email_reply_parser lets you grab the last reply in an ongoing thread. The other libraries, pickle and json, will be used for I/O.
import indicoio
indicoio.config.api_key = 'YOUR_API_KEY'
from email_reply_parser import EmailReplyParser
import pickle
import json
The sentiment_sliding function looks at 1,000-word windows from your sent emails, shifting forward by 20 words at a time (first window would be 0-1,000 and the next window would be 20-1,020, etc.). The moving window approach works well for smoothing out short term fluctuations while revealing long term trends.
def sentiment_sliding(messages, window=1000, shift=20):
allwords = []
data = {}
for m in messages:
if 'Sent' not in m.get('folders', tuple()):
continue
if not m.get('body') or not m['body'].get('content'):
continue
allwords.append(EmailReplyParser.parse_reply(m['body']['content']))
allwords = " ".join(allwords)
allwords = allwords.encode('ascii','ignore')
allwords = allwords.split()
current_window = 0
next_window = window
print 'number of words', len(allwords)
while True:
if len(allwords) Finally we have the I/O code that lets you run the em.py script to generate a pickle file with your metadata.
f = open('email.json','r')
rawemails = json.load(f)
print 'number of emails', len(rawemails)
f.close()
data = sentiment_sliding(rawemails)
with open('data.pkl', 'wb') as f:
pickle.dump(data, f)
Lastly, boot up IPython Notebook (now known as Jupyter Notebook) and run each of the following cells from viz_sentiment.ipynb to produce a seaborn scatter plot with your sentiment values.
%matplotlib inline
import pandas as pd
import seaborn as sns
metadata = pd.io.pickle.read_pickle('data.pkl')
munge = []
for w, s in metadata.items():
munge.append({'wordnum': w, 'sentiment': s})
df = pd.DataFrame.from_records(munge)
sns.regplot('wordnum', 'sentiment', df, color='seagreen')
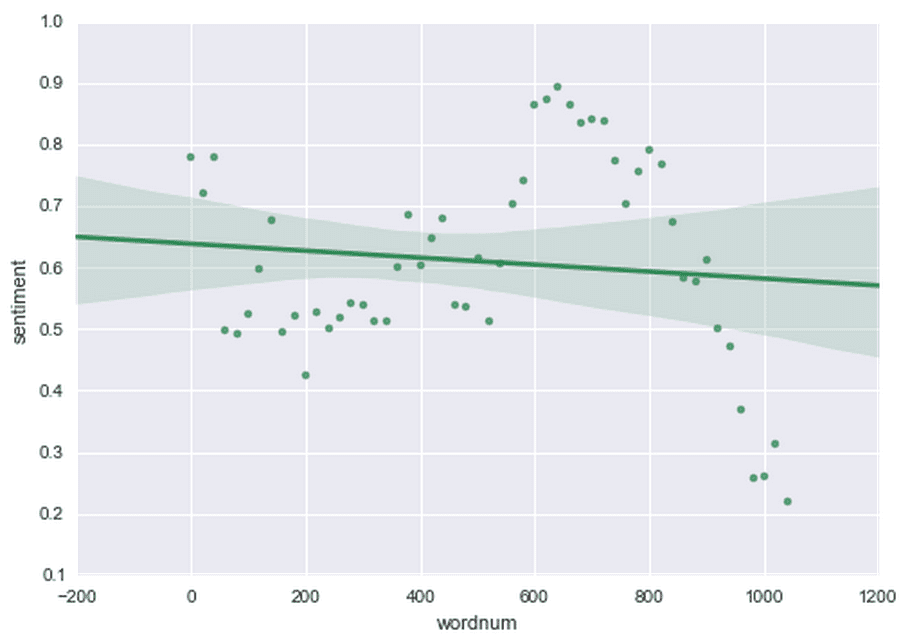
While I don’t want to jump to any conclusions, here is Madison’s take on the findings…

All code from this tutorial is housed at github.com/IndicoDataSolutions/examples/tree/master/email.
For more on how our models work, refer to indico.io/models.
.
Effective January 1, 2020, Indico will be deprecating all public APIs and sunsetting our Pay as You Go Plan.
Why are we deprecating these APIs?
Over the past two years our new product offering Indico IPA has gained a lot of traction. We’ve successfully allowed some of the world’s largest enterprises to automate their unstructured workflows with our award-winning technology. As we continue to build and support Indico IPA we’ve reached the conclusion that in order to provide the quality of service and product we strive for the platform requires our utmost attention. As such, we will be focusing on the Indico IPA product offering.
